
Introduction
Transformations in data processing refer to the operations applied to raw data to modify, refine, or structure it for analysis. They help convert data into a more useful format, ensuring it meets business or analytical requirements.
Types of Data Transformations:
- Cleansing – Removing duplicates, handling missing values, and standardizing formats.
- Filtering – Selecting specific data based on conditions (e.g., only records after 2020).
- Aggregation – Summarizing data, such as calculating totals, averages, or counts.
- Joining/Merging – Combining datasets from multiple sources based on common keys.
- Mapping – Converting values from one format to another (e.g., currency conversions).
- Enrichment – Adding external data to enhance information (e.g., geolocation, demographics).
- Pivoting & Reshaping – Changing the data structure for reporting or visualization.
Where Transformations Are Used:
- ETL (Extract, Transform, Load) pipelines for data integration.
- Big data processing for analytics and machine learning models.
- Data warehousing to structure information for reporting.
- Cloud computing workflows like Azure Data Factory and Synapse Analytics.
Let’s take a deep dive into transformations and use cases with Azure services.
Understanding Transformations in Azure Data Factory (ADF)
Azure Data Factory serves as a cloud-based data integration and orchestration service, enabling ETL workflows across multiple sources. While ADF does not natively process data within itself, it provides robust options for transforming data via Mapping Data Flows and external compute engines.
Types of Transformations in ADF
– Mapping Data Flows (For Low-Code Transformations)
- Ideal for: Structured transformations where simplicity is preferred (joins, aggregations, pivots, derived columns).
- Built-in, Spark-based execution running on Azure behind the scenes.
- Best for: Operational data processing where transformations are straightforward and repeatable without writing code.
– External Processing via Compute Engines (For Complex Logic)
- Leverages: Azure Databricks, HDInsight (Hadoop/Spark), Azure SQL, and Azure Functions.
- Best suited for: Large-scale transformations requiring machine learning, deep data manipulation, or advanced analytics.
- Example Scenario: When needing custom Python or Spark transformations, ADF calls Databricks notebooks or executes SQL stored procedures in Synapse/SQL.
Key Use Case Decisions for ADF
- Use ADF when the primary goal is data orchestration.
- Best when integrating diverse sources (on-prem, multi-cloud, APIs, etc.).
- Ideal when transformations require external compute resources (Databricks, HDInsight, SQL Server).
When not to use ADF
- Not ideal for in-place transformations inside a data warehouse.
- Not optimized for high-performance, SQL-based processing within structured datasets.
Understanding Transformations in Azure Synapse Analytics
Azure Synapse Analytics is a big data analytics and data warehousing solution that enables in-database transformations at scale, leveraging SQL-based processing and Spark-based distributed execution.
Types of Transformations in Synapse
– SQL-Based Transformations (For Structured Data Processing)
- Best when dealing with: Large, structured datasets that require joins, aggregations, window functions, and query optimization.
- Runs on Dedicated SQL pools, Serverless SQL pools, or Synapse Pipelines.
- Ideal for: Querying structured tables in Azure Synapse or performing ETL operations directly within SQL Data Warehouses.
– Spark-Based Transformations (For Big Data Processing)
- Best when handling: Unstructured or semi-structured data (JSON, Parquet, CSV from Data Lakes).
- Executes distributed computations across clusters in Synapse Spark pools.
- Example Scenario: When processing large-scale IoT data, logs, and real-time datasets, Spark in Synapse is preferred over SQL due to its distributed nature.
Key Use Case Decisions for Synapse
- Use Synapse when transformations need to happen inside the warehouse for faster analytics.
- Best for SQL-driven ETL in structured datasets.
- Use Synapse Spark for unstructured data transformations within a data lake.
When not to use Synapse
- Not ideal for orchestrating multi-source data movement (ADF is better here).
- Not optimized for hybrid or multi-cloud integration (ADF provides better connectivity).
Decision Matrix: Choosing Between ADF and Synapse for Transformations
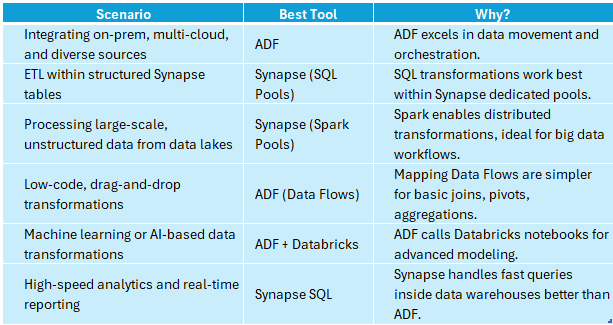

Navigating Transformation Decisions
While working on a unique project—one of the first of its kind at my company—I faced the challenging decision of selecting the right transformation approach. At the early stages, foundational architectural choices are critical, yet the uncertainty of future scalability and evolving requirements adds complexity to decision-making.
Initially, the project required robust ETL pipelines, but the balance between flexibility (Azure Data Factory) and performance-driven in-warehouse processing (Synapse Analytics) wasn’t straightforward. Given that the data workflows were not yet well-defined, I needed a solution that would allow rapid iteration while ensuring efficiency once the system scaled.
Key challenges included:
- Unpredictable Data Structures: Since the project was evolving, data sources varied widely, making ADF’s multi-source orchestration highly appealing.
- Performance vs. Adaptability: Synapse Analytics was optimized for structured, high-performance transformations, but ADF provided more freedom for integrating diverse datasets in an exploratory phase.
- Future-Proofing the Architecture: The early-stage nature meant that locking into one transformation model too soon might limit flexibility later.
Ultimately, the decision required balancing immediate needs with long-term vision. ADF provided the agility needed for experimentation, while Synapse proved invaluable as the project matured into structured processing. This experience reinforced the importance of understanding transformation tools—not just theoretically, but in real-world applications where ambiguity and evolution shape technical choices.
Final Thoughts: Balancing ADF and Synapse for Data Processing
Azure Data Factory is the choice for orchestration, handling data movement, multi-source integration, and workflow automation. On the other hand, Azure Synapse Analytics is the powerhouse for data warehousing and big-data transformations, delivering SQL-based processing and Spark-driven analytics at scale.
For hybrid ETL architectures, the best approach often combines ADF for data movement with Synapse for in-place transformations, ensuring efficient data ingestion, transformation, and analytics.

Leave a comment