
In the world of machine learning, neural networks are often described as systems that mimic the human brain. But what gives these networks their intelligence? At the heart of every neural network lie two critical components: weights and biases. These parameters are the true levers that allow a model to learn, adapt, and make predictions.
Let’s break down what they are, why they matter, and how they work together to power modern AI systems.
What Are Weights?
In a neural network, weights determine the strength of the connection between two neurons. Each input to a neuron is multiplied by a weight — a learnable parameter that tells the network how important that input is.
Think of weights like volume knobs — they control how loudly each input “speaks” to the next layer.
Mathematically:
For an input x and weight w, the contribution to the neuron is:
w \cdot x
During training, the model adjusts these weights to minimize the error between its predictions and the actual outcomes.
What Is a Bias?
While weights scale the input, biases shift the output. A bias allows the activation function to be offset, giving the model more flexibility to fit the data.
If weights are the slope of a line, the bias is the y-intercept — it shifts the entire function up or down.
Full Neuron Equation:
z = w \cdot x + b
Where:
- w = weight
- x = input
- b = bias
- z = input to the activation function
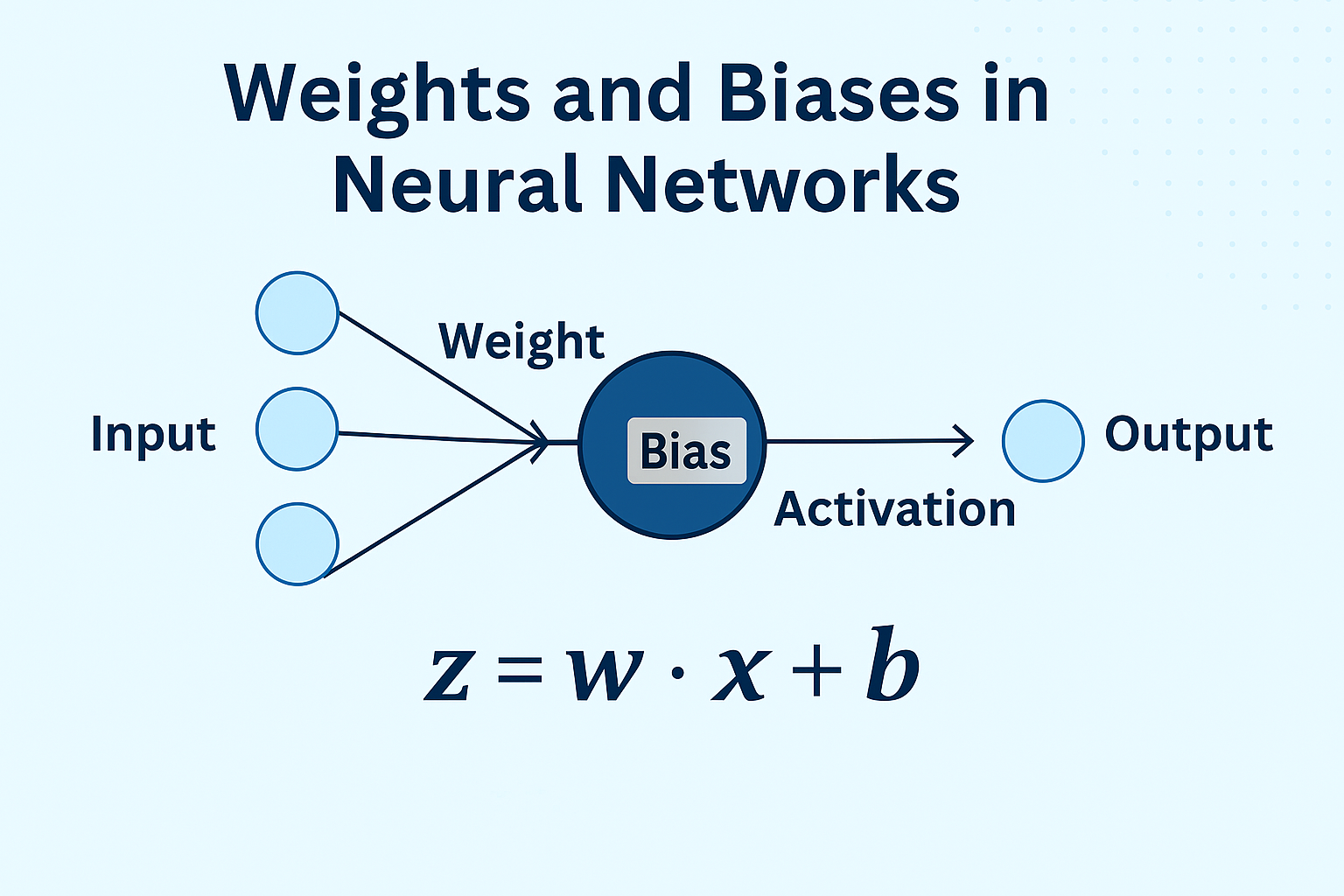
How Do They Work Together?
When data flows through a neural network:
- Each input is multiplied by its corresponding weight.
- The results are summed and the bias is added.
- This value is passed through an activation function (like ReLU or sigmoid).
- The output is sent to the next layer.
This process repeats across layers, allowing the network to learn complex patterns.
What Happens During Training?
Training a neural network means finding the optimal set of weights and biases that minimize prediction error. This is done using:
- Loss functions (e.g., mean squared error, cross-entropy)
- Backpropagation (to compute gradients)
- Optimization algorithms (like SGD or Adam)
Each iteration updates the weights and biases slightly, nudging the model closer to better performance.
Why They Matter?
| Component | Role | Impact |
|---|---|---|
| Weight | Scales input | Determines feature importance |
| Bias | Shifts output | Adds flexibility to the model |
| Together | Define the model’s behavior | Enable learning and generalization |
Without weights and biases, a neural network would be nothing more than a static function — incapable of learning or adapting.
Final Thoughts
Weights and biases may seem like small details, but they are the core learning mechanisms of neural networks. Every prediction, every classification, every insight generated by an AI model is shaped by these parameters.
Whether you’re building a simple feedforward network or fine-tuning a large language model, understanding how weights and biases work is essential to mastering deep learning.




Leave a comment